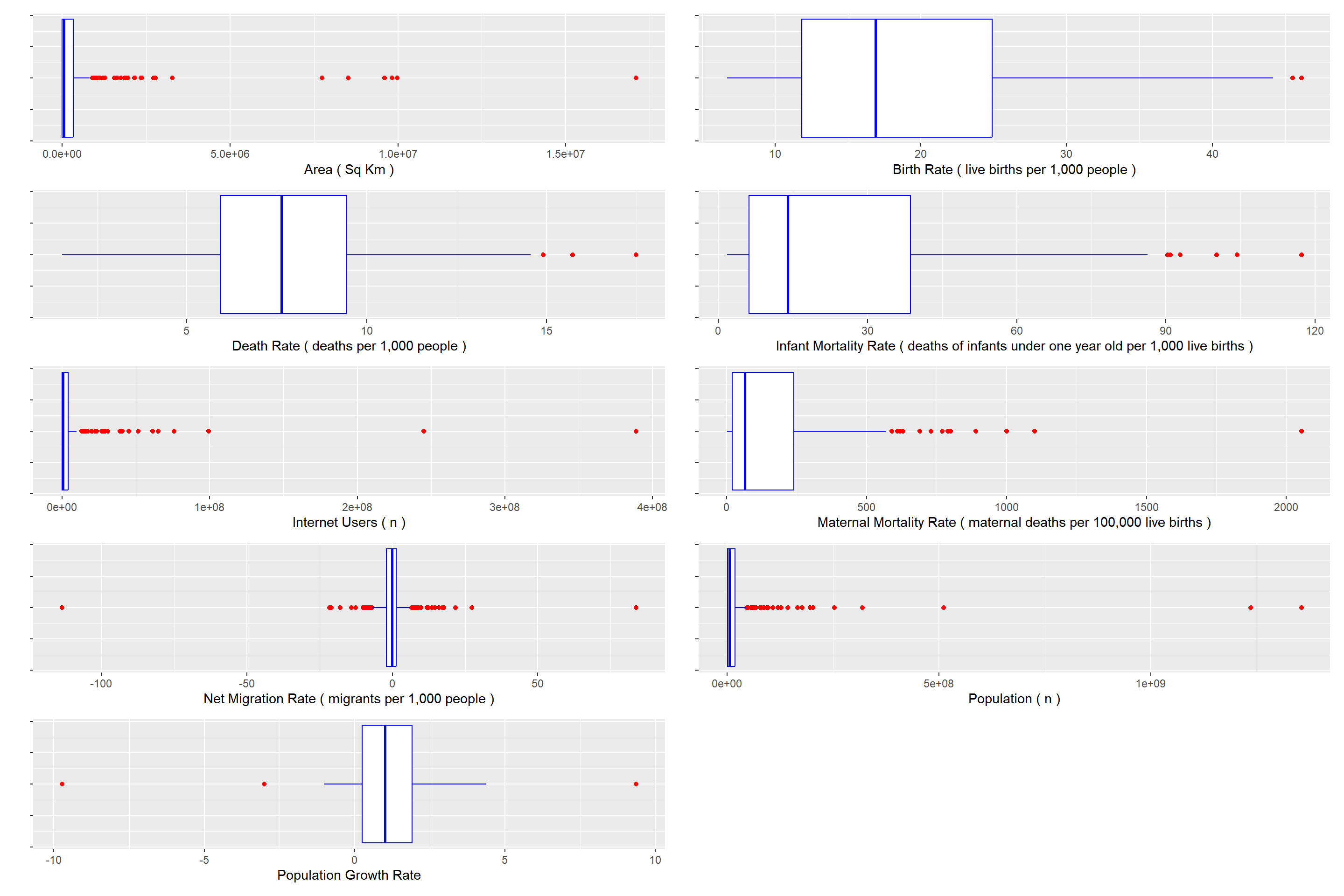
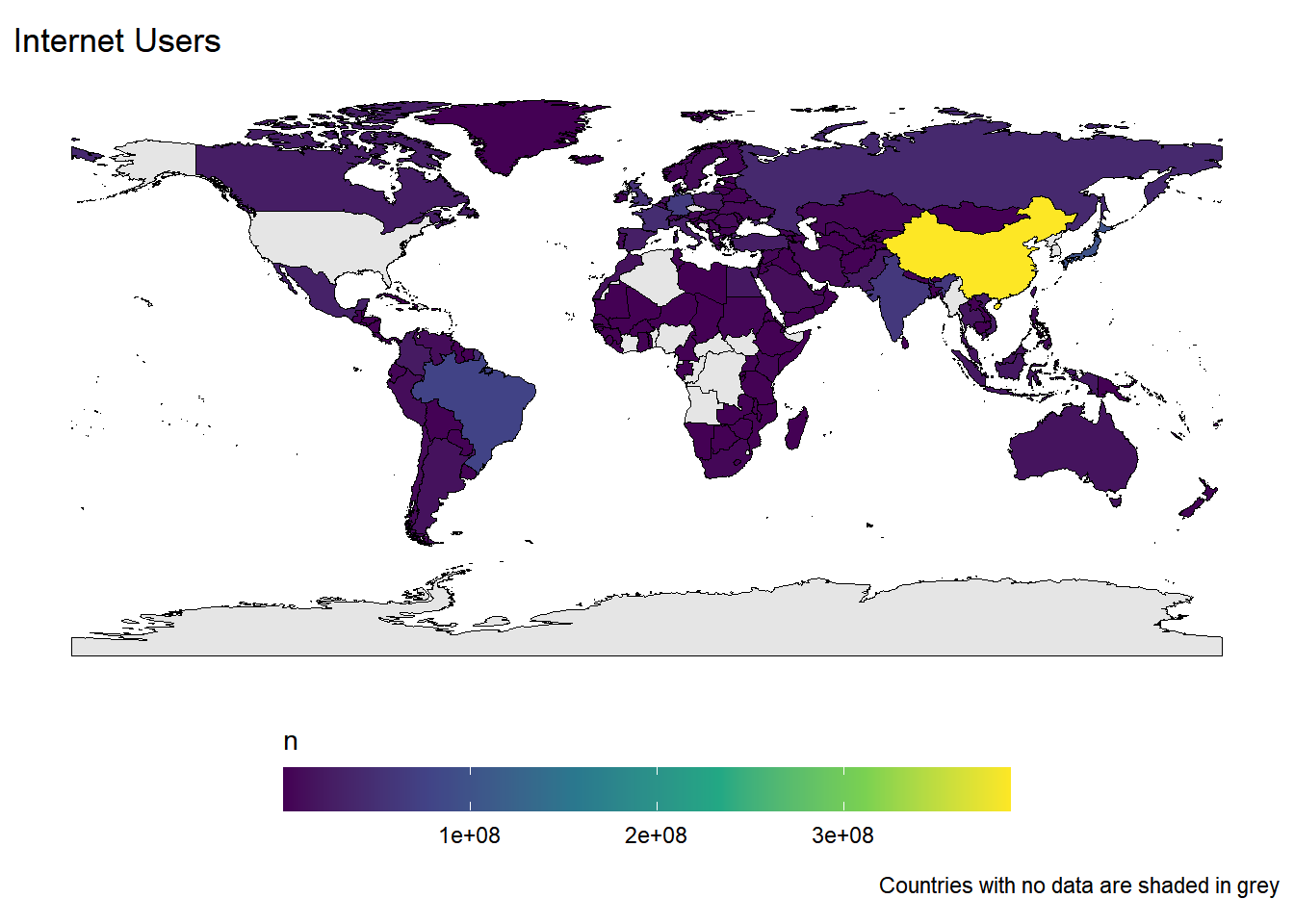
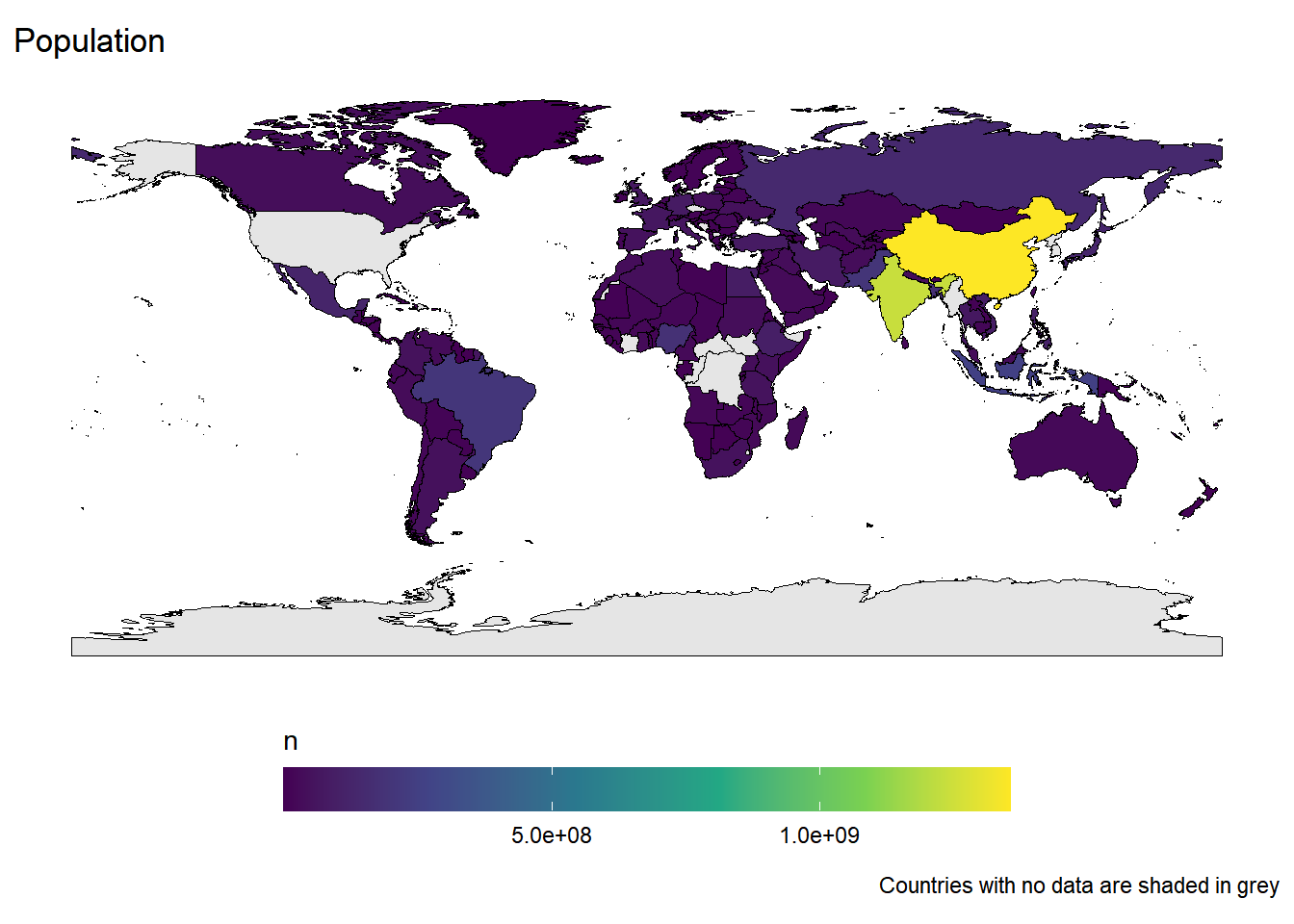
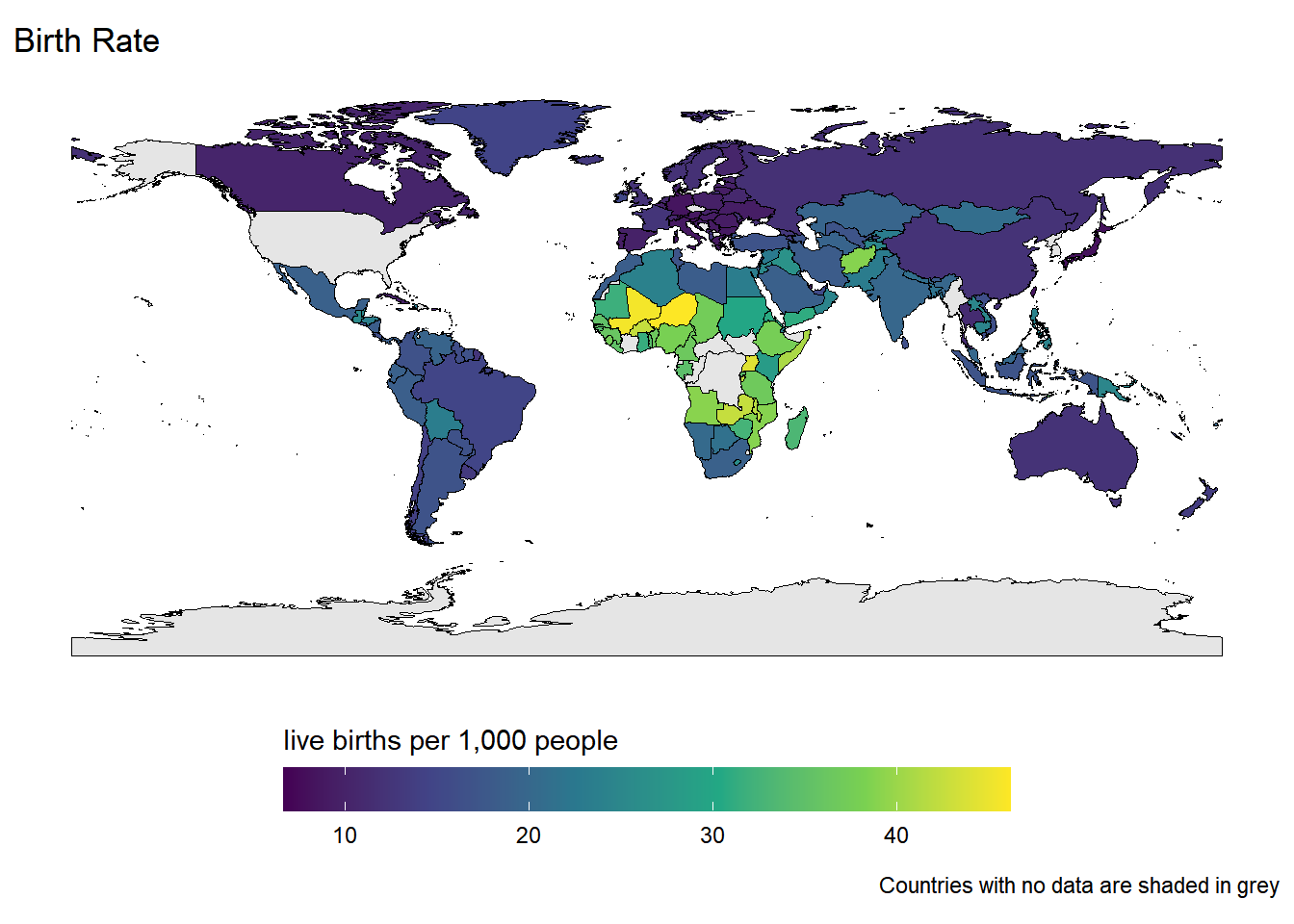
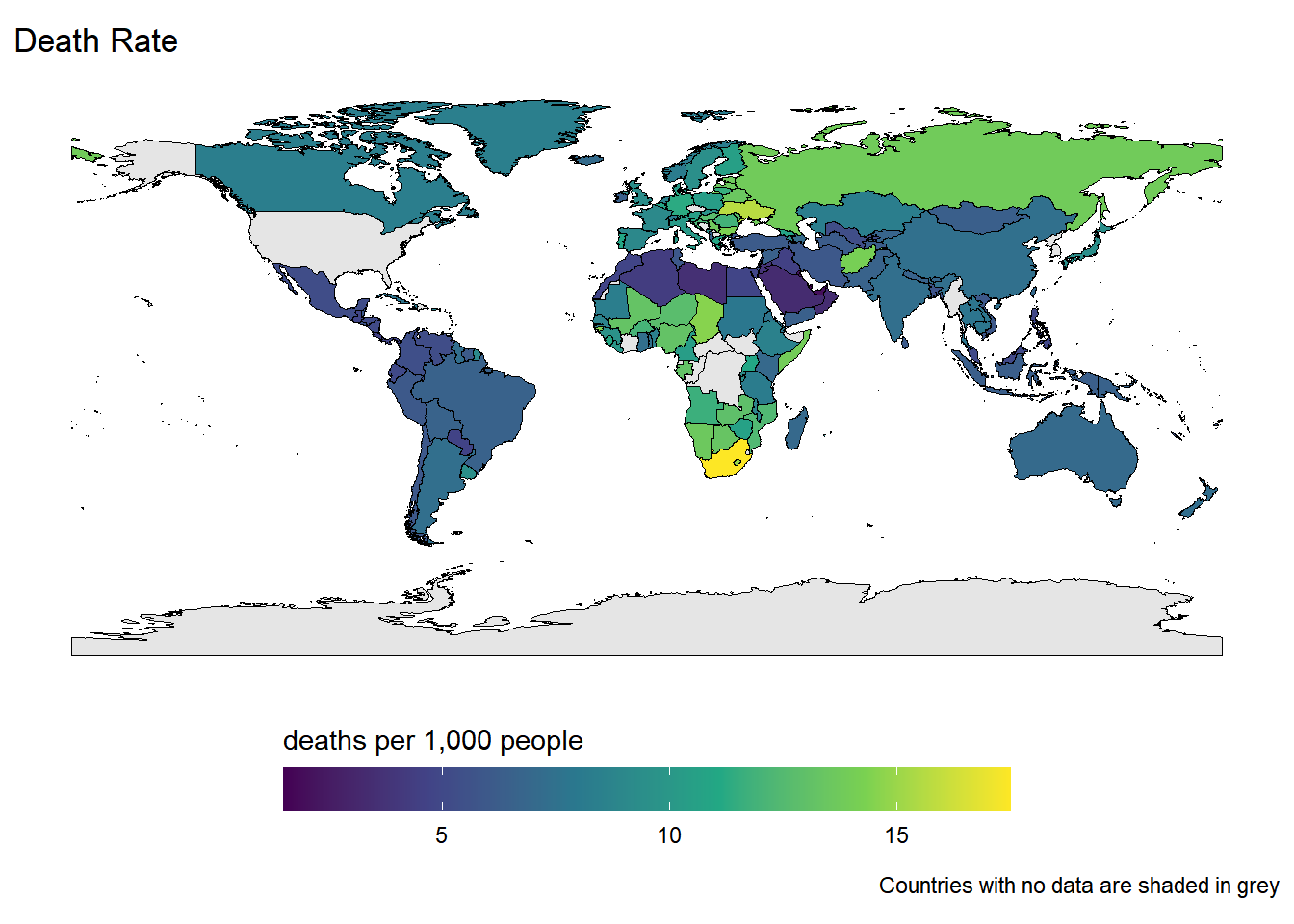
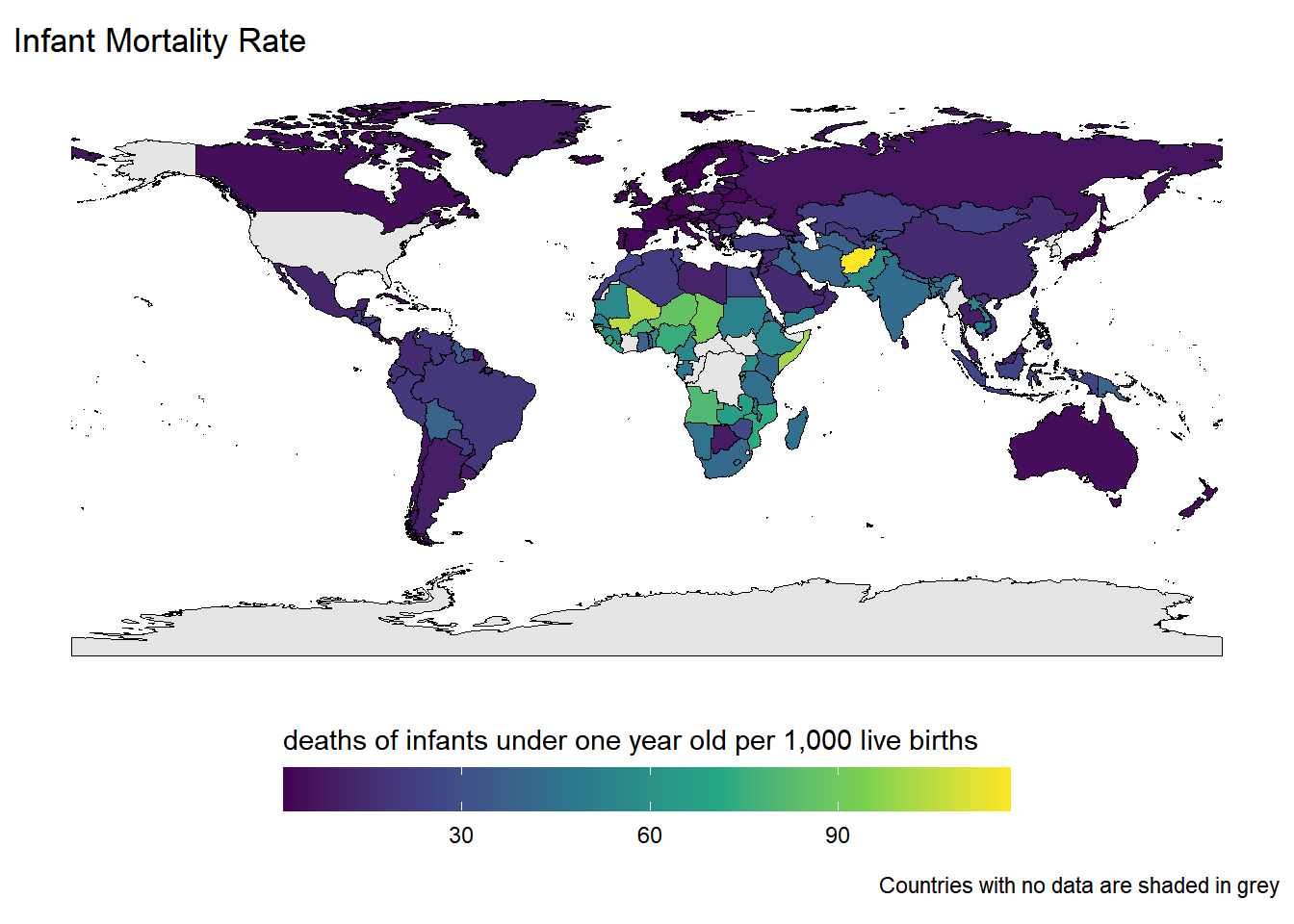
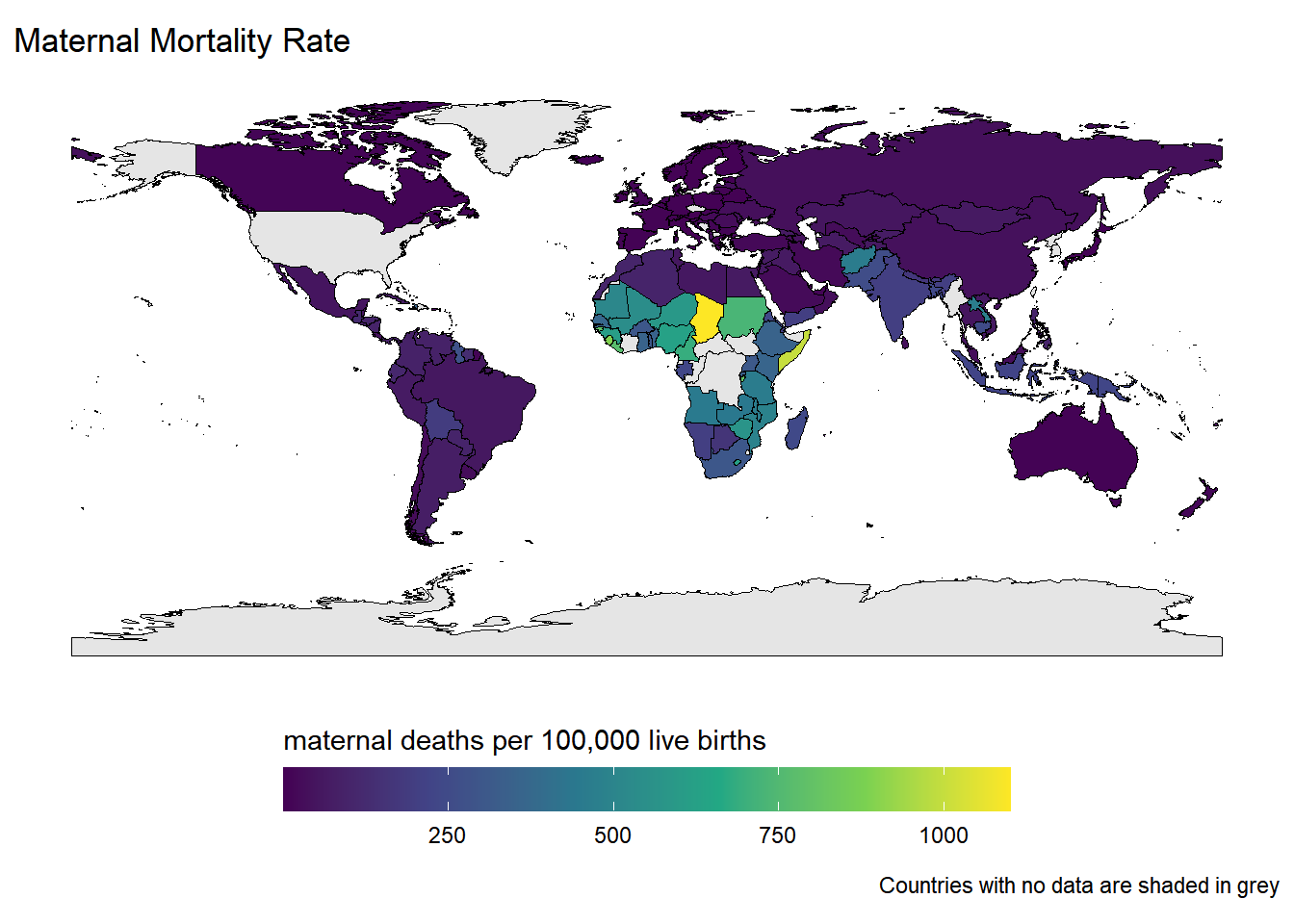
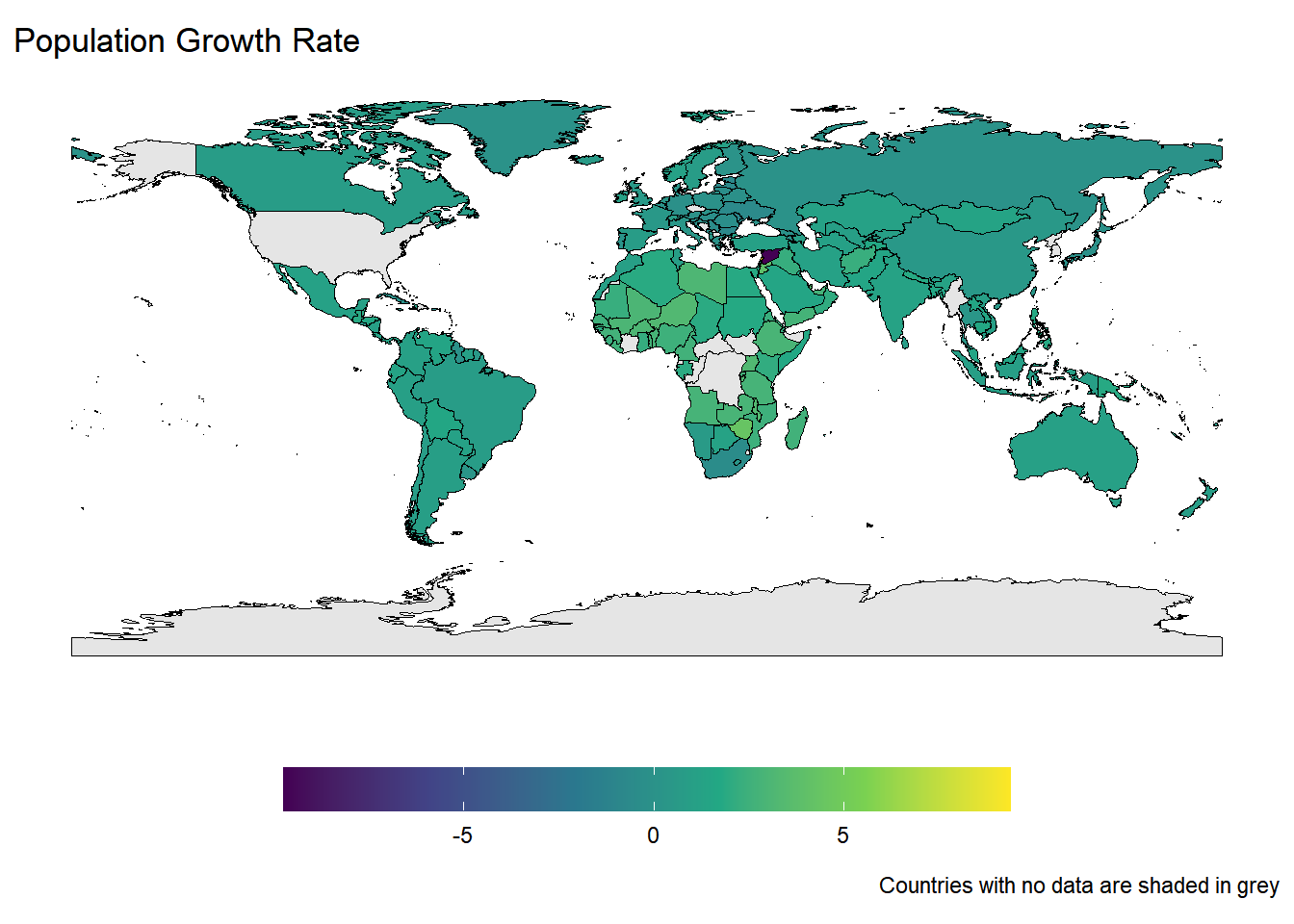
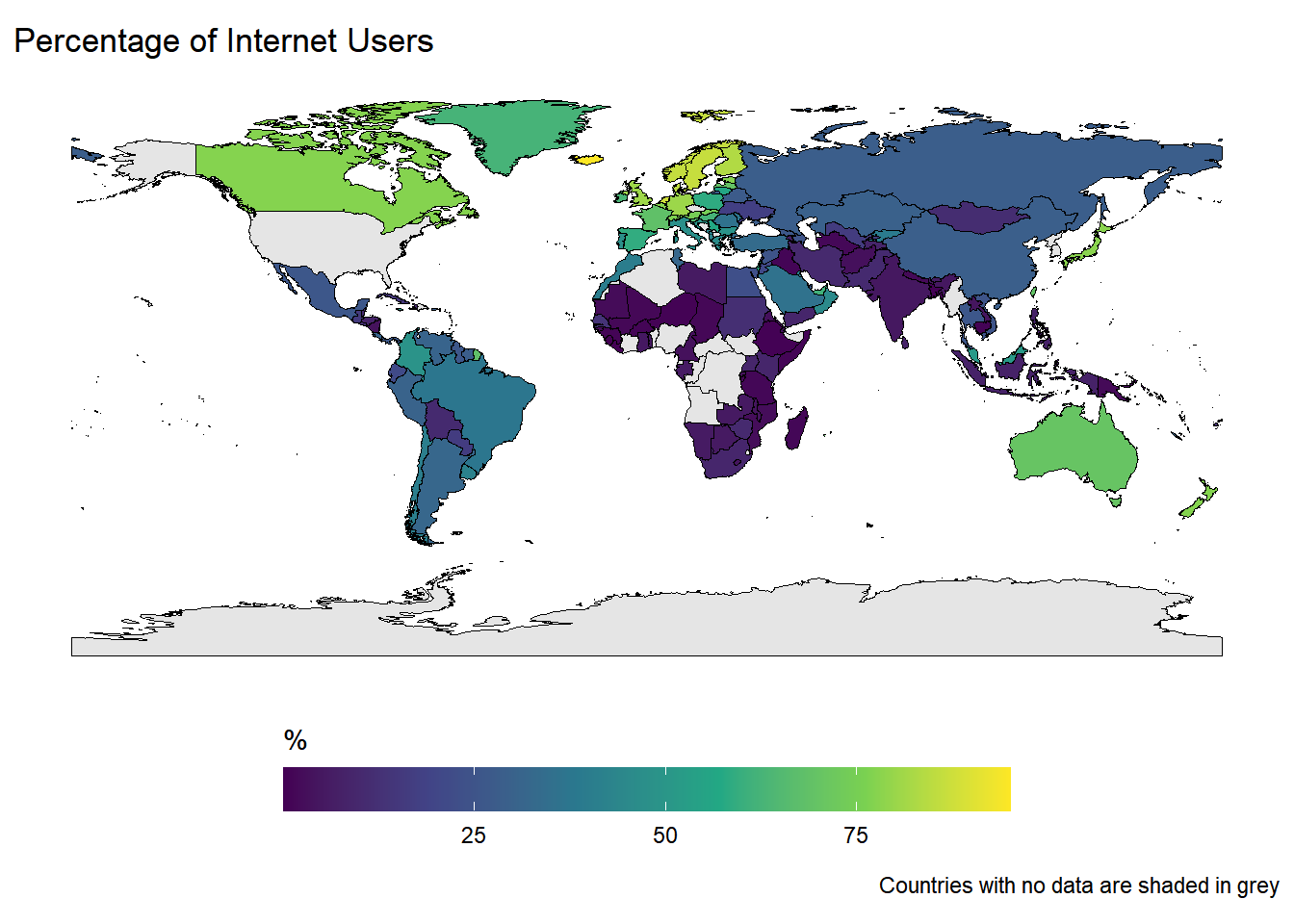
Rows: 259
Columns: 11
$ country <chr> "Russia", "Canada", "United States", "China", …
$ area <dbl> 17098242, 9984670, 9826675, 9596960, 8514877, …
$ birth_rate <dbl> 11.87, 10.29, 13.42, 12.17, 14.72, 12.19, 19.8…
$ death_rate <dbl> 13.83, 8.31, 8.15, 7.44, 6.54, 7.07, 7.35, 7.3…
$ infant_mortality_rate <dbl> 7.08, 4.71, 6.17, 14.79, 19.21, 4.43, 43.19, 9…
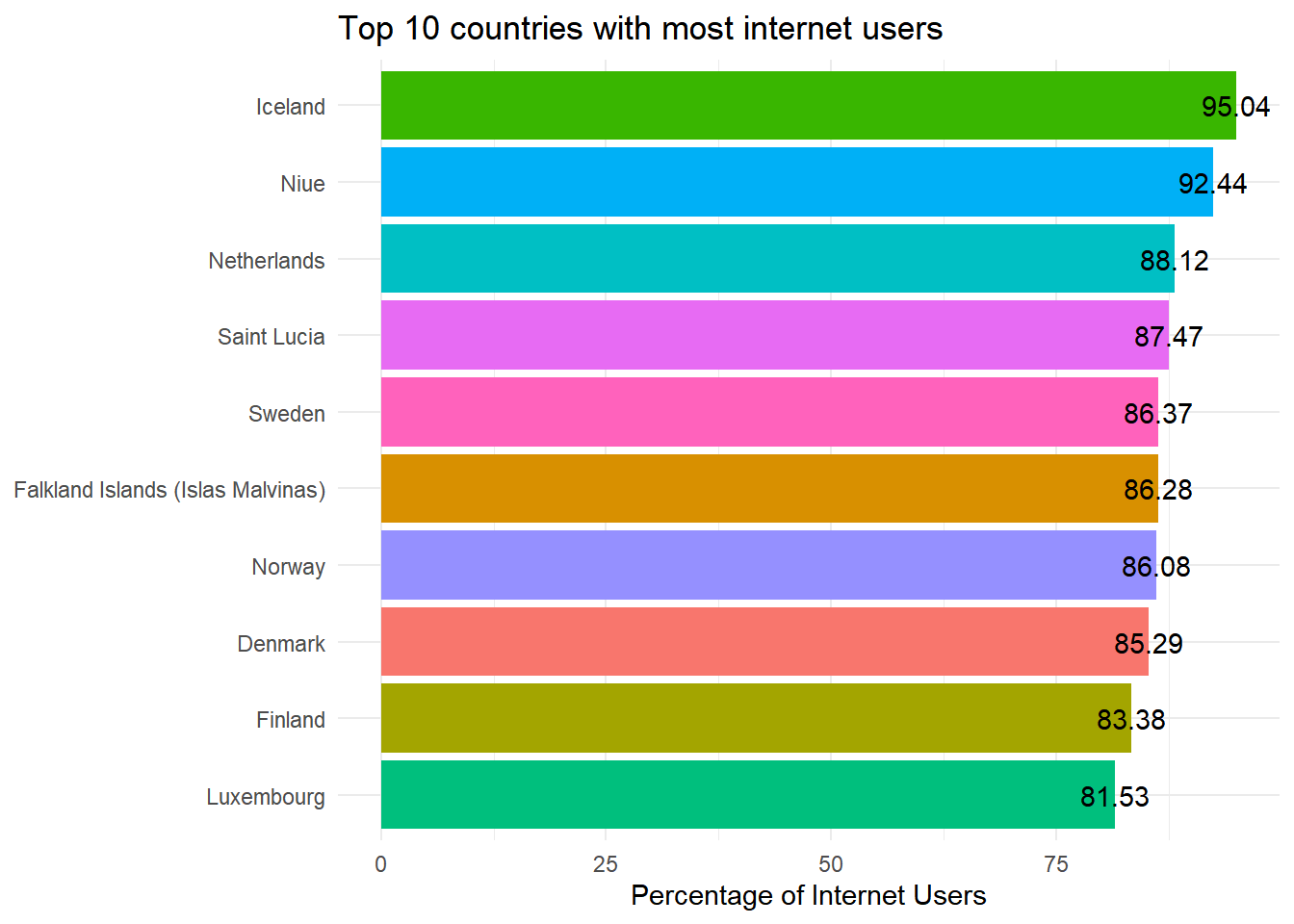
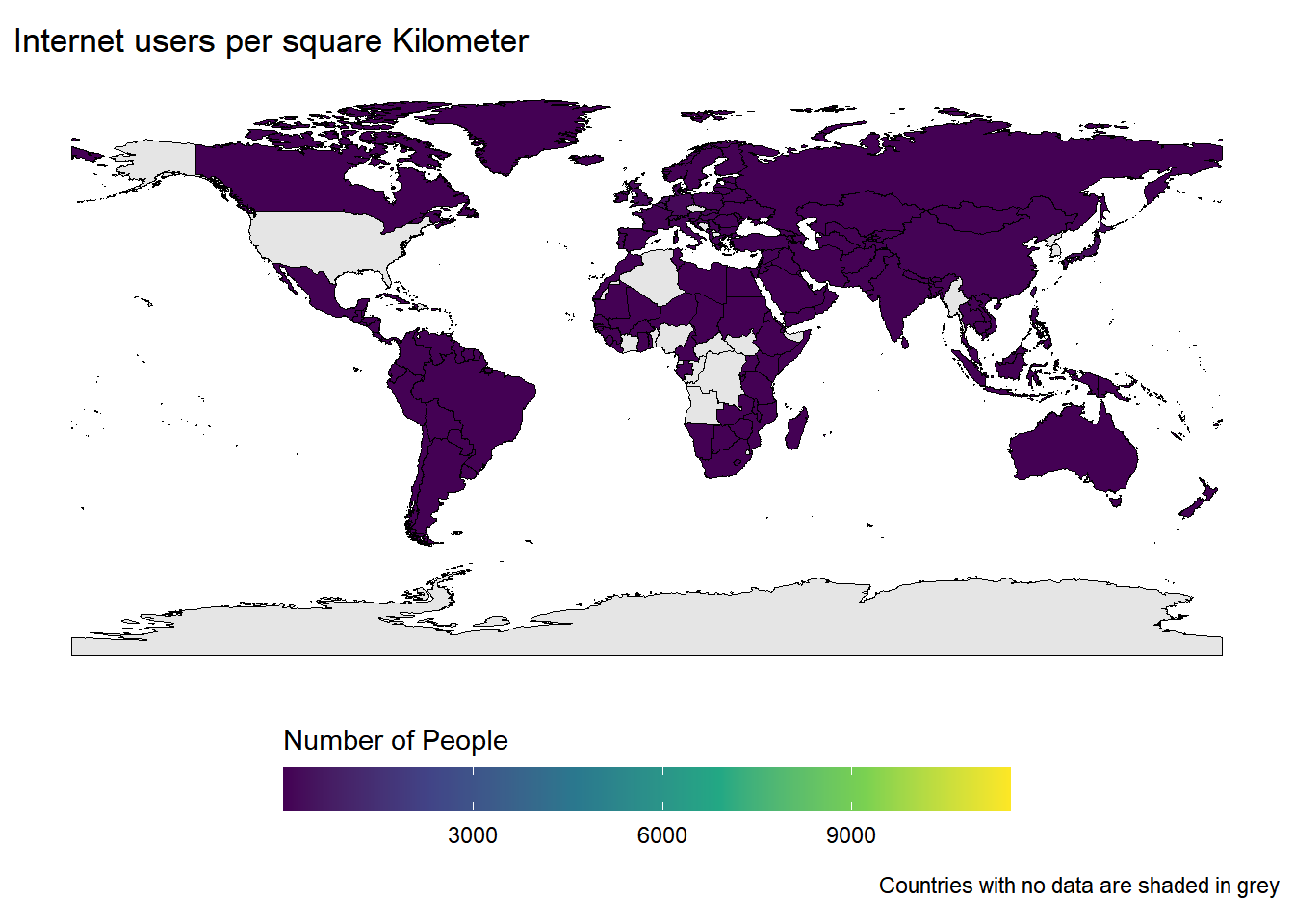
$ internet_users <dbl> 40853000, 26960000, 245000000, 389000000, 7598…
$ life_exp_at_birth <dbl> 70.16, 81.67, 79.56, 75.15, 73.28, 82.07, 67.8…
$ maternal_mortality_rate <dbl> 34, 12, 21, 37, 56, 7, 200, 77, 51, 97, 540, N…
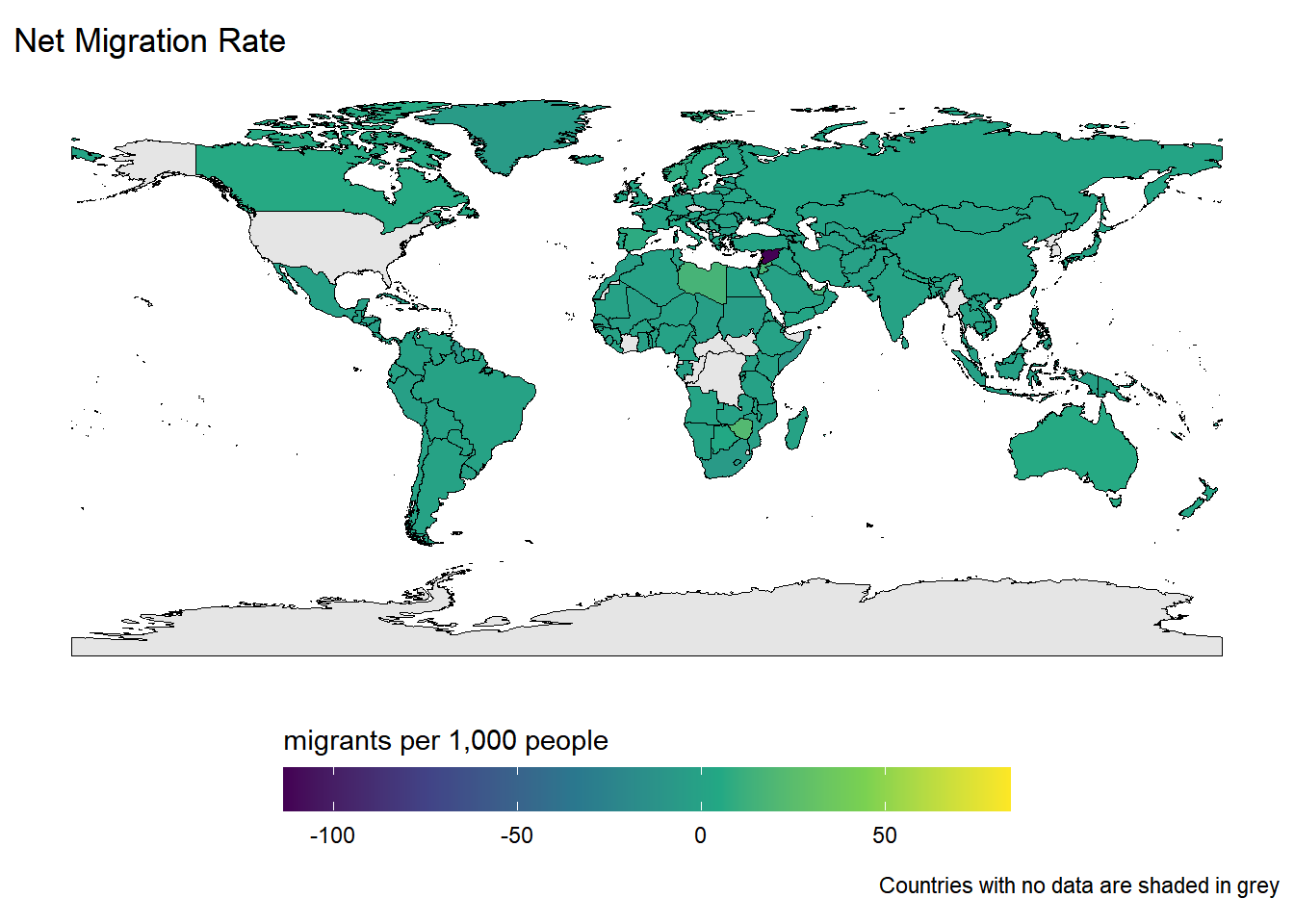
$ net_migration_rate <dbl> 1.69, 5.66, 2.45, -0.32, -0.15, 5.74, -0.05, 0…
$ population <dbl> 142470272, 34834841, 318892103, 1355692576, 20…
$ population_growth_rate <dbl> -0.03, 0.76, 0.77, 0.44, 0.80, 1.09, 1.25, 0.9…